Spark SQLで使えるUDF(user defined function)を定義する
コラビットの川原です。
今日はApache SparkのUDFについて簡単に説明します。
SparkにおけるUDF(user defined function)とは
UDFは使いこなすと大変便利な仕組みです。
しっかり理解して活用することで簡潔なコードで分析を進めることができます。
Spark SQL
まず、そもそもApache SparkではSpark SQLという構造化されたデータをSQLで操作できるモジュールが用意されています。
具体的に説明します。
例えば、下記のようにcsvファイルを読み取ったデータフレームに対してcreateOrReplaceTempViewを実行します。
// csvを読み取りval somethingData = spark.read.option("header", true).option("inferSchema", true).option("nullValue", "NULL").csv("some/where/something-data.csv")// tempViewとして登録somethingData.createOrReplaceTempView("something_data")
そうすると、下記のようにSQLでデータを操作することができます。
spark.sql("SELECT id, address FROM something_data")sqlDF.show()// showメソッドは下記のような標準出力となります// +----+----------+// | id| address|// +----+----------+// | 1| 阿佐ヶ谷|// | 2| 阿佐ケ谷|// | 3| 高円寺|// | 4| 中野|// +----+----------+
UDFはSQLでSELECTする時に使える独自の関数を定義できる
Spark SQLは便利なツールなのですが、普通のDBだと使える関数が使えなかったりすることがあります。
「あーー、なんかうまく処理してくれる関数があれば便利なのになあ。。。」とか思ったときは、UDFの出番です。
UDFはどうやって使うのか?
UDFを使うときはあらかじめ定義する必要があります。
spark.sqlContext.udfに対してregisterメソッドを実行します。
第一引数には名前、第二引数には高階関数を指定します。
下記は文字列を正規化するためのUDFです。
spark.sqlContext.udf.register("normalizedWord", (str: String) => {// 阿佐ヶ谷、押上(スカイツリー前)などの正規化str.replace("ケ", "ヶ").replaceAll("〈.+〉", "")})
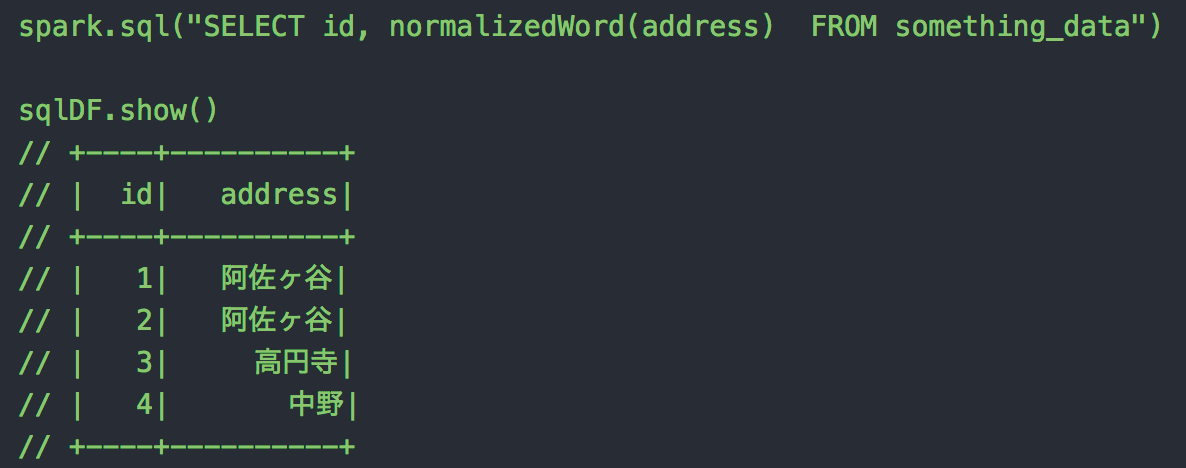
これを定義した上、下記のようにSpark SQLを実行してみましょう
spark.sql("SELECT id, normalizedWord(address) FROM something_data")sqlDF.show()// +----+----------+// | id| address|// +----+----------+// | 1| 阿佐ヶ谷|// | 2| 阿佐ヶ谷|// | 3| 高円寺|// | 4| 中野|// +----+----------+
阿佐ヶ谷が正規化された文字列で表示されています。
SQLも簡潔な記述となっておりよいですね。
以上Apache Sparkで使えるUDFの紹介でした。