回帰分析のPMMLの内容について解説します
コラビットの川原です。
今回は前回、書いたopenscoringの記事を社内で紹介したところ、「PMMLってなに?」、「どんなこと書いてあるの?」と色々と反響があったので、
PMMLの実態や読み方について紹介したいと思います。
PMMLについてふりかえり
PMML(predictive model markup language)とは統計モデルの内容をXMLにしたものです。
Rやscikit-leran、Apache Sparkなど色々な機械学習ツールから変換ができるので、モデルのデプロイの際に役立つツールです。
最近ではPFA(Portable Format for Analytics)というjsonやyamlで統計モデルを管理する仕組みもあるようです。しかし、弊社ではApache Sparkを使ってモデルの計算をしておりいまだに、PMMLを使っています。
scikit-learnなどローカル環境で実行するものはPFAに対応しており、Sparkなどの分散環境で動かすものについては、まだPMMLにしか対応してない、というのが現在(2018年5月時点)の状況です。なので、分析するデータ規模に応じて、両方の使い分けをする必要があります。
今回はPMMLについて理解を少しだけ深めてみたいと思います。
PMMLの実態
PMMLの中身はXMLです。
下記は簡単な回帰分析のモデルのPMMLです。
[xml]
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<PMML xmlns="http://www.dmg.org/PMML-4_3" version="4.3">
<Header>
<!– ①ヘッダー情報です。 –>
</Header>
<DataDictionary>
<!– ②データのスキーマ情報が記載されています。 –>
</DataDictionary>
<TransformationDictionary>
<!– ③データを変換する手順が記載されています。 –>
</TransformationDictionary>
<RegressionModel functionName="regression">
<!– ④回帰分析の詳細について記載されています。 –>
</RegressionModel>
</PMML>
[/xml]
次の項目では各所を具体的に解説していきたいと思います。
PMMLにはどんなことが書いてあるのか?
①の部分にはモデルの任意の名前やタイムスタンプなどが記載されています。
[xml]
<Header>
<Application name="JPMML-SparkML" version="1.4.2"/>
<Timestamp>2018-05-22T23:09:31Z</Timestamp>
</Header>
[/xml]
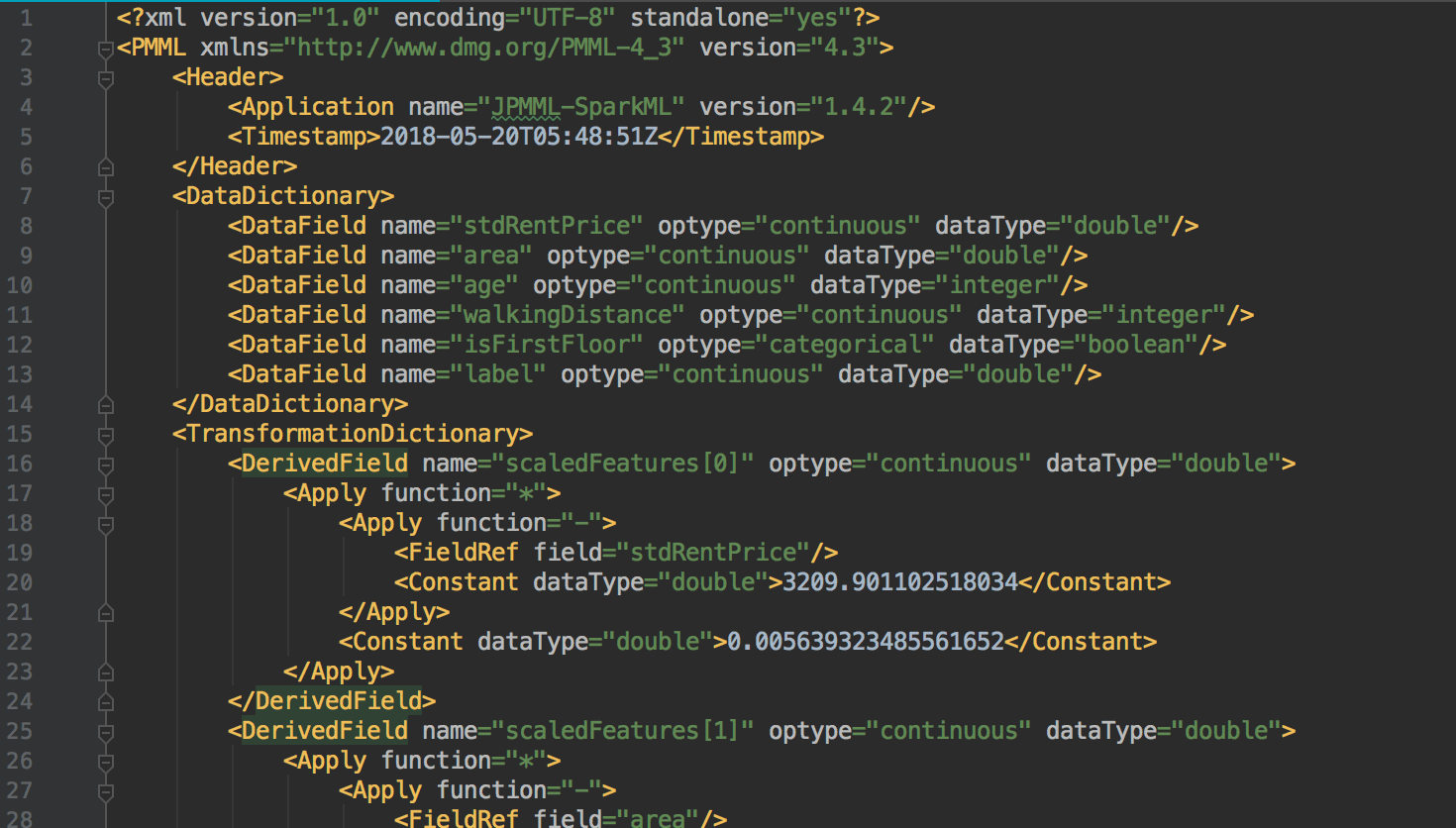
②の部分には説明変数および被説明変数について記載されています。
[xml]
<DataDictionary>
<DataField name="area" optype="continuous" dataType="double"/>
<DataField name="age" optype="continuous" dataType="integer"/>
<DataField name="walkingDistance" optype="continuous" dataType="integer"/>
<DataField name="isFirstFloor" optype="categorical" dataType="boolean"/>
<DataField name="label" optype="continuous" dataType="double"/>
</DataDictionary>
[/xml]
変数の名称や型、量的変数か質的変数なのか定義されていることがわかります。
③の部分にはデータを変換する手順について記載されています。例えば、標準化したり、主成分分析したりなどです。
[xml]
<TransformationDictionary>
<DerivedField name="scaledFeatures[0]" optype="continuous" dataType="double">
<Apply function="*">
<Apply function="-">
<FieldRef field="stdRentPrice"/>
<Constant dataType="double">2956.1834316299514</Constant>
</Apply>
<Constant dataType="double">0.005639323485561644</Constant>
</Apply>
</DerivedField>
<!– 本当は説明変数ごとに上記の記載がありますが割愛してます。 –>
</TransformationDictionary>
[/xml]
上記は標準化の変換です。平均を引いた後に1/標準偏差をかけています。
(一応割り算(/)も対応しているのですが jpmml-sparkml で生成したPMMLでは掛け算(*)になっていました。)
functionに指定できるものは他にも色々定義されています
* min, max, sum, avg, median, product
* log10, ln, sqrt, abs, exp, pow, threshold, floor, ceil, round
* ほかにもいっぱいです。詳しくは公式ドキュメント(英語)を見るのがよいです。
④の部分には回帰分析の詳細が記載されています。
[xml]
<RegressionModel functionName="regression">
<MiningSchema>
<MiningField name="label" usageType="target"/>
<MiningField name="area"/>
<MiningField name="age"/>
<MiningField name="walkingDistance"/>
<MiningField name="isFirstFloor"/>
</MiningSchema>
<Output>
<OutputField name="prediction" optype="continuous" dataType="double" feature="predictedValue"/>
</Output>
<RegressionTable intercept="2543.8758624118573">
<NumericPredictor name="scaledFeatures[0]" coefficient="177.32623470888075"/>
<NumericPredictor name="scaledFeatures[1]" coefficient="-140.81473092051385"/>
<NumericPredictor name="scaledFeatures[2]" coefficient="-278.8696326135456"/>
<NumericPredictor name="scaledFeatures[3]" coefficient="-25.250608617077585"/>
</RegressionTable>
</RegressionModel>
[/xml]
説明変数および被説明変数や切片や係数が書いてあります。
係数の値は適当なので精査しないようにお願いします(汗)
中身をそのまま読むと、意外と簡単な内容だということがわかります。
今回は単純な回帰分析のPMMLの内容について紹介しましたが、他にもアルゴリズムに応じて色々な記載方法があります。
PMMLはフレームワークによらず、モデルの内容を記載できる大変便利なツールです。
より理解を深めていきたいですね。
参考URL